
Architectural Distinctions: Structured Outputs Versus Function Calling in Modern Language Model Systems
The landscape of artificial intelligence is rapidly evolving beyond simple conversational interfaces, pushing towards the development of sophisticated, autonomous agents capable of complex interactions and decision-making. At the heart of this transformation lies a critical architectural choice for developers: how to enable language models (LMs) to produce predictable, machine-readable outputs and interact seamlessly with external environments. While LMs inherently operate on a text-in, text-out paradigm, the demand for reliable software pipelines and autonomous agents necessitates a departure from raw, unstructured text. This imperative has led major LM API providers, including OpenAI, Anthropic, and Google Gemini, to introduce two primary mechanisms: structured outputs and function calling. Though seemingly similar in their ability to yield structured data, these capabilities serve fundamentally distinct architectural purposes, and a clear understanding of their differences is paramount for building robust, efficient, and cost-effective AI applications. Conflating the two can lead to brittle architectures, unnecessary latency, and inflated API costs, underscoring the importance of a well-informed decision-making framework.
The Evolution of LLM Interaction: From Raw Text to Programmatic Control
Historically, interacting with large language models primarily involved providing a text prompt and receiving a text response. This was adequate for casual chat interfaces but presented significant challenges for integrating LMs into deterministic software systems. Parsing unstructured natural language outputs for specific data points or actions proved unreliable, requiring extensive post-processing, validation, and error-handling logic. This limitation became a bottleneck as ambitions grew to deploy LMs in critical applications, ranging from automated customer service agents to complex data analysis pipelines.
The first attempts to bridge this gap often relied on "prompt engineering," where developers would instruct the model, for instance, "You are a helpful assistant that only speaks in JSON." While innovative, this method was inherently error-prone. The model, designed for natural language generation, could easily deviate from the strict JSON format, necessitating multiple retries and complex validation layers. This era highlighted the need for more robust, native mechanisms to enforce output structure and facilitate external interaction, paving the way for the sophisticated features available today.
Differentiating the Mechanisms: A Deep Dive
To effectively leverage structured outputs and function calling, practitioners must grasp their underlying mechanical and API-level distinctions. While both typically involve passing JSON schemas to the API and result in structured key-value pairs, their operational principles and intended applications diverge significantly.
-
Structured Outputs: Enforcing Form through Grammar-Constrained Decoding
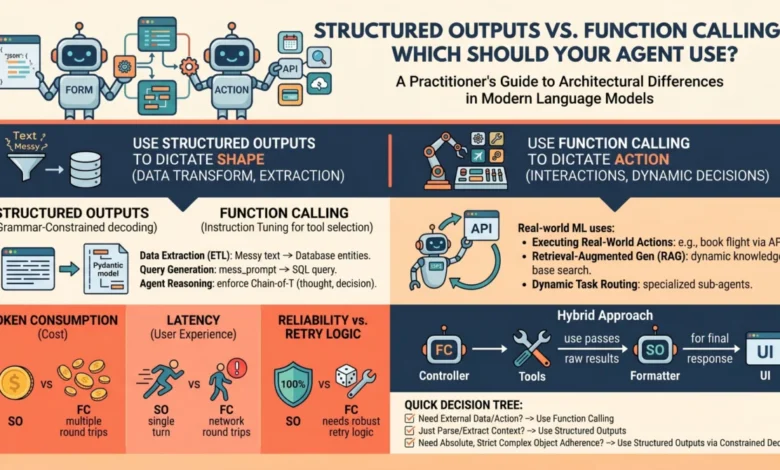
Structured outputs represent a fundamental shift from heuristic prompt engineering to a mathematically enforced guarantee of output format. This mechanism primarily focuses on controlling the form of the model’s direct response to a prompt. Instead of merely suggesting a format, modern implementations utilize grammar-constrained decoding. Libraries such as Outlines, or native features like OpenAI’s Structured Outputs, work by dynamically restricting the token probabilities during the generation process. If a predefined schema dictates that the next token must be a quotation mark, a specific boolean value, or a numerical digit, the probabilities of all non-compliant tokens are effectively masked out or set to zero. This ensures that the model generates an output that adheres almost 100% to the specified JSON schema or other structured format (e.g., XML, YAML).
This process is inherently a single-turn generation. The model receives a prompt and a schema, and its task is to provide a direct answer, but with its vocabulary confined to the exact structure defined by the schema. The model is not performing an action or interacting with an external system; it is merely re-shaping or extracting information already present or inferable from the initial prompt and context window. The primary goal is data transformation, extraction, or standardization, ensuring high reliability and eliminating schema-parsing errors on the client side.
-
Function Calling: Enabling Autonomous Interaction through Instruction Tuning
Function calling, in contrast, is designed to enable an LM to interact with the external world and execute specific actions or retrieve information not contained within its immediate context. Its mechanics are rooted in instruction tuning, a process where models are fine-tuned on vast datasets to recognize situations where they lack necessary information or when a user’s prompt explicitly requests an action. During this training, the model learns to pause its text generation and instead generate a structured call to a predefined "tool" or "function" with the appropriate arguments.
When a developer provides a model with a list of available tools (defined by their signatures and descriptions, often in JSON schema format), they are essentially instructing the model: "If you need to, you can temporarily halt your generation, select a tool from this list, and generate the necessary arguments to execute it." This is an inherently multi-turn, interactive flow:
- The user sends a prompt to the LM.
- The LM determines if a tool call is necessary. If so, it generates a structured function call (e.g.,
"tool_name": "get_weather", "arguments": "location": "London"). - The application developer intercepts this function call, executes the actual
get_weatherfunction (which queries an external API), and retrieves the result. - The result of the tool execution is then passed back to the LM as part of the conversation history.
- The LM, now equipped with the new information, continues its text generation or makes further tool calls as needed, ultimately providing a comprehensive response to the user.
Function calling is the engine of agentic autonomy, dictating the control flow of an application by allowing the model to dynamically decide when and how to interact with external systems.
Architectural Nuances and Practical Applications
The choice between structured outputs and function calling carries significant implications for system architecture, reliability, latency, and cost.
-
When to Choose Structured Outputs:
Structured outputs should be the default choice whenever the primary goal is pure data transformation, extraction, or standardization of information already present within the prompt or context window. The model has all the necessary information; it just needs to reshape it into a predictable format.Examples for Practitioners:
- Data Extraction: Extracting entities (names, dates, locations, product IDs) from unstructured text fields (e.g., customer reviews, support tickets) into a structured JSON object for database storage or further analysis.
- Content Summarization with Metadata: Generating a summary of an article along with structured metadata (author, keywords, publication date, sentiment score) in a consistent format.
- Form Processing: Converting free-form user input from a text field into a structured data object for a backend system (e.g., converting "I need a flight from New York to London next Tuesday" into
"departure": "New York", "destination": "London", "date": "next Tuesday"). - Configuration Generation: Generating configuration files (e.g., YAML, JSON) based on a natural language description of desired settings.
- Code Generation (Structured Snippets): Generating small, well-defined code snippets (e.g., a function signature, a data structure definition) in a specific programming language format.
The verdict: Use structured outputs when the "action" is simply formatting or extracting data. Because there is no mid-generation interaction with external systems, this approach ensures high reliability, lower latency (typically a single API call), and zero schema-parsing errors on the client side. Industry reports suggest that enterprises leveraging structured outputs can reduce manual parsing and validation efforts by up to 90% compared to traditional prompt engineering, leading to faster development cycles and more robust data pipelines.
-
When to Choose Function Calling:
Function calling is indispensable when the model needs to interact with the outside world, fetch information it doesn’t currently possess, or dynamically execute software logic mid-thought. It is the cornerstone of truly autonomous agents.Examples for Practitioners:
- Conversational Agents with External Capabilities: A chatbot that can book flights, check weather, set reminders, or query a knowledge base by calling specific APIs.
- Dynamic Data Retrieval: An agent that needs to look up a user’s order history from an e-commerce database before responding to a query about a recent purchase.
- Automated Workflow Execution: An agent that can initiate a series of steps in a business process, such as creating a support ticket, escalating an issue, or sending an email, based on user input.
- Complex Reasoning with Tools: An agent that can use a calculator tool for mathematical problems, a search engine for current events, or a code interpreter for debugging.
- Personalized Recommendations: An agent that fetches user preferences and product availability from different databases to offer tailored recommendations.
The verdict: Choose function calling when the model must interact with the outside world, retrieve "hidden" data, or conditionally execute software logic during its reasoning process. This approach is crucial for building agents that can adapt, learn, and perform complex tasks that extend beyond their immediate training data.
Performance, Latency, and Cost: A Critical Analysis
When deploying AI agents to production, the architectural choice between these two methods directly impacts unit economics and user experience.
- Latency: Structured outputs are generally faster. They involve a single, direct generation process. Function calling, being multi-turn and interactive, inherently introduces higher latency due to the round-trip network calls required for tool execution and subsequent model inferences. Each tool call adds at least one extra API call to the LM and one call to the external tool, significantly increasing the total response time. For user-facing applications where real-time interaction is critical (e.g., chatbots), this can be a crucial differentiator.
- Cost: The cost implications are directly tied to latency and the number of API calls. Structured outputs typically incur a single inference cost. Function calling, however, involves multiple inference calls for each turn of interaction, potentially leading to significantly higher API costs, especially for complex tasks requiring several tool uses. Furthermore, the tool descriptions (function signatures) themselves consume token context, adding to the input token count for every turn, even if the tool isn’t called.
- Reliability: Structured outputs offer near 100% schema compliance due to grammar-constrained decoding, making them exceptionally reliable for data formatting. Function calling, while powerful, introduces points of failure. The model might misinterpret when to call a tool, generate incorrect arguments, or the external tool itself might fail. Robust error handling and retry mechanisms are essential when implementing function calling.
- Developer Experience: While both require schema definition, function calling demands more complex orchestration logic on the developer’s side to manage the multi-turn interaction, execute tools, and handle potential failures. Structured outputs offer a simpler integration for pure data transformation tasks.
Hybrid Approaches and Best Practices
In advanced agent architectures, the line between structured outputs and function calling often blurs, leading to powerful hybrid approaches. It’s worth noting that modern function calling relies on structured outputs under the hood to ensure the generated arguments match the function signatures defined in the schema. Conversely, a developer can design an agent that exclusively uses structured outputs to return a JSON object describing an action that a deterministic system should execute after the generation is complete—effectively "faking" tool use without the multi-turn latency.
Architectural Advice:
- Prioritize Simplicity: Always default to structured outputs if the task can be achieved without external interaction. This minimizes latency, cost, and complexity.
- Layer Functionality: When function calling is necessary, encapsulate tools effectively. Design tools to be modular and single-purpose to reduce the model’s cognitive load in selecting and using them correctly.
- Embrace Determinism: Use structured outputs for all internal data transformation and validation within your agent’s reasoning steps, even if those steps are part of a larger function-calling flow. This provides predictable intermediate states.
- Robust Error Handling: For function calling, implement comprehensive error handling, retry logic, and fallback mechanisms for when tools fail or the model generates incorrect calls. Consider "guardrails" to prevent unintended or malicious tool executions.
- Observability: Implement robust logging and monitoring for both mechanisms, especially for function calls, to understand how the agent is making decisions and interacting with external systems.
The Broader Impact on AI Development and Expert Consensus
The emergence of robust structured outputs and function calling mechanisms marks a pivotal moment in LM engineering, signifying a transition from crafting mere conversational chatbots to building reliable, programmatic, autonomous agents. This shift empowers developers to integrate LMs more deeply into enterprise applications, automating complex workflows and creating intelligent systems that can adapt and interact dynamically.
Leading AI platform providers universally emphasize the strategic importance of these features. OpenAI, for instance, highlights its function calling capabilities as a core component for "connecting LMs to external tools and APIs," while Google Gemini and Anthropic similarly stress the need for structured interaction for enterprise-grade applications. The consensus among AI researchers and practitioners is that while language models are becoming increasingly capable, their true utility in real-world, mission-critical scenarios hinges on their ability to produce predictable outputs and interact programmatically with their environment.
The implications for developer productivity are substantial. By offloading the complexities of natural language parsing and action orchestration to the LM itself, developers can focus on defining business logic and integrating external services, accelerating the development of sophisticated AI applications. However, this power also brings responsibility; understanding how to constrain and direct models effectively is key to building agents that are not only intelligent but also safe, reliable, and controllable.
The Practitioner’s Decision Tree
When building a new feature or designing an agent, a quick 3-step checklist can guide the architectural choice:
-
Does the model need to interact with external systems (APIs, databases, services) to complete the task or fetch necessary information?
- Yes: Lean towards Function Calling.
- No: Proceed to step 2.
-
Does the output need to be in a strictly enforced, machine-readable format (e.g., JSON, XML) for downstream processing, even if the information is entirely within the prompt?
- Yes: Use Structured Outputs.
- No: Proceed to step 3.
-
Can the task be accomplished with raw, unstructured text output, or is a simple conversational response sufficient?
- Yes: Use standard text generation.
- No: Re-evaluate if steps 1 or 2 were missed, or if the problem requires a combination of approaches.
Final Thought
The most effective AI engineers recognize function calling as a powerful but inherently less predictable capability, one that should be used judiciously and surrounded by robust error handling and monitoring. Conversely, structured outputs should be treated as the reliable, foundational glue that holds modern AI data pipelines together, ensuring consistency and minimizing the friction between the fluid world of natural language and the rigid requirements of programmatic systems. Mastering these distinctions is not merely a technical exercise; it is a strategic imperative for shaping the future of autonomous and intelligent software.


{kind=link}