
Ethereum’s Ascent to $5,000: A Marathon, Not a Sprint, According to Predictive Algorithms
The cryptocurrency market, perpetually characterized by its volatility and speculative fervor, has once again brought Ethereum (ETH) into the spotlight, not for a record-breaking surge, but for its relatively subdued performance in the wake of Bitcoin’s monumental ascent. While the digital gold, Bitcoin, shattered previous ceilings, reaching stratospheric heights beyond $100,000 during the last bull run, its closest competitor, Ethereum, found itself playing catch-up. The much-anticipated parabolic rise for ETH, mirroring its historical patterns, failed to materialize as significantly. Instead, the second-largest cryptocurrency by market capitalization merely nudged past its prior all-time high by a modest $100, ultimately remaining below the psychologically significant $5,000 mark. This performance has left many investors questioning the future trajectory of ETH, particularly its prospects of breaching the $5,000 threshold.
A Gradual Climb: The Long Road to $5,000
Predictive algorithms, designed to forecast the future value of digital assets, offer a nuanced perspective on Ethereum’s potential. CoinCodex, a prominent platform for cryptocurrency price predictions, employs a multifaceted approach, factoring in a wide array of variables to project price movements across various timeframes, from short-term fluctuations to long-term decades-long trends. Their analysis of Ethereum’s future price trajectory, while predominantly bullish due to sustained investor interest and ongoing network development, suggests that a significant re-test of previous all-time highs and a definitive move beyond the $5,000 mark will not be an overnight phenomenon. Instead, the projections point towards a more gradual ascent, with substantial rallies anticipated over a span of several years.
This outlook directly challenges some of the more optimistic forecasts from various cryptocurrency analysts who had posited that Ethereum could surpass $5,000 by as early as 2026. CoinCodex’s algorithm, however, paints a more conservative picture. For the year 2026, it projects a peak price of $4,445, effectively placing a new all-time high above $5,000 out of reach within that timeframe. This suggests that while the ecosystem remains robust, the market dynamics and inherent valuation drivers for ETH may necessitate a longer period for such a significant price appreciation.
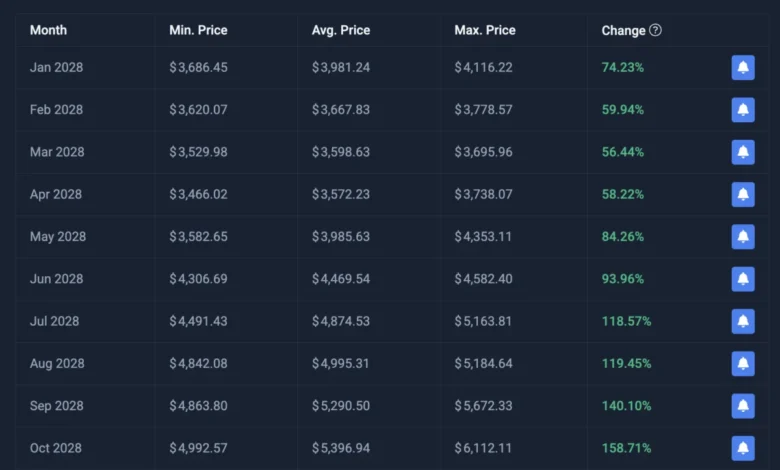
The algorithm’s refined projection indicates that it could take several years for Ethereum to finally breach the $5,000 barrier. The specific forecast places this milestone in the third quarter of 2028. This implies that investors might need to exercise patience, with approximately two more years of market development and potential price discovery before ETH can confidently establish itself above this critical price level. This extended timeline underscores the inherent cyclical nature of cryptocurrency markets and the multitude of factors that influence price action, beyond just immediate investor sentiment.
The Elusive $10,000 Mark: A Distant Horizon
The aspiration for Ethereum to reach a five-figure valuation, specifically the $10,000 mark, appears to be an even more distant prospect, according to the prevailing algorithmic predictions. The struggles Ethereum has faced in keeping pace with Bitcoin’s explosive growth have contributed to this more conservative outlook. The CoinCodex algorithm does not foresee Ethereum touching $10,000 before the year 2030, a timeline that aligns with some industry predictions but also suggests a significant period of sustained growth and adoption will be required.

However, a deeper dive into the predictive chart reveals an even more protracted timeline for this ambitious target. The first discernible indication of Ethereum reaching $10,000 within the analyzed data set emerges after the year 2040. This implies that the journey to a $10,000 ETH could potentially span well over a decade, a stark contrast to the rapid ascents witnessed in previous bull cycles. Such a long-term forecast emphasizes the need for sustained technological advancements, widespread utility, and favorable macroeconomic conditions to propel Ethereum to such unprecedented valuations.
Short-Term Optimism Amidst Long-Term Patience
Despite the extended timelines for reaching higher price targets, the short-term outlook for Ethereum remains decidedly optimistic. The predictive algorithm anticipates double-digit percentage gains for ETH in the upcoming month, signaling potential immediate price appreciation. Furthermore, the projections suggest a doubling of Ethereum’s price within the next three months, with a high forecast of $4,298 anticipated by the end of the second quarter. This near-term bullish sentiment is likely fueled by ongoing developments within the Ethereum ecosystem, such as the successful implementation of protocol upgrades and the increasing adoption of decentralized applications (dApps) built on its blockchain.
The recent price action of Ethereum, as depicted in trading charts, shows a period of retracement following a prior rally. This is a common occurrence in volatile markets, where periods of rapid ascent are often followed by consolidation or pullbacks as traders take profits or re-evaluate market conditions. However, the underlying strength of the Ethereum network and its ecosystem continues to be a significant driver of investor confidence. The transition to Proof-of-Stake (PoS) through "The Merge" has fundamentally altered the network’s economics, reducing issuance and introducing staking rewards, which can positively influence long-term supply dynamics and investor demand.
Contextualizing Ethereum’s Performance: The Post-Bitcoin Surge Landscape
To understand Ethereum’s current position, it’s crucial to revisit the dynamics of the last major bull run. During that period, Bitcoin’s meteoric rise created a powerful ripple effect across the entire cryptocurrency market. Investors, emboldened by Bitcoin’s success, sought out other promising digital assets, with Ethereum often being the primary beneficiary due to its established market position and broad utility. The narrative was one of synchronized growth, where the success of Bitcoin was seen as a precursor to similar, if not identical, parabolic movements in altcoins.
However, the market has matured since then. While Bitcoin continues to hold its status as the dominant digital asset, the cryptocurrency landscape has become more diverse and complex. Ethereum, while still the second-largest, faces increased competition from other smart contract platforms and has its own set of challenges and opportunities. The scaling solutions being developed for Ethereum, such as layer-2 rollups, are crucial for its long-term viability and ability to handle a growing number of transactions without exorbitant fees. The success of these scaling efforts will undoubtedly play a significant role in its future price performance.
Investor Sentiment and Market Influences
Investor sentiment towards Ethereum remains a critical factor. Despite the recent underperformance relative to Bitcoin’s peak, the fundamental value proposition of Ethereum – its role as the backbone for decentralized finance (DeFi), non-fungible tokens (NFTs), and a growing array of Web3 applications – continues to attract significant investment. The total value locked (TVL) in Ethereum-based DeFi protocols, while subject to market fluctuations, has historically demonstrated the platform’s immense utility and economic activity.

Furthermore, macroeconomic factors, such as global inflation rates, interest rate policies of central banks, and regulatory developments surrounding cryptocurrencies, all exert a considerable influence on asset prices. A prolonged period of economic uncertainty or stricter regulatory environments could potentially temper the growth of digital assets, including Ethereum. Conversely, a more favorable economic climate and clear regulatory frameworks could accelerate adoption and price appreciation.
Broader Implications for the Crypto Ecosystem
The projected timelines for Ethereum’s price milestones have broader implications for the entire cryptocurrency ecosystem. If it takes several years for ETH to reach $5,000 and over a decade to approach $10,000, it suggests a more sustained and potentially less speculative growth phase for the market. This could foster greater institutional adoption, as longer-term investment horizons become more viable. It also allows more time for technological innovation and the development of robust use cases that can support these higher valuations.
The differential growth rates between Bitcoin and Ethereum also highlight the evolving nature of the digital asset market. While Bitcoin remains the primary store of value and a digital gold narrative, Ethereum is increasingly being recognized for its utility as a decentralized computing platform. This distinction could lead to diverging price dynamics, where Bitcoin’s price might be more influenced by macro-economic factors and its scarcity, while Ethereum’s price is more closely tied to its network activity, developer adoption, and the success of its ecosystem.
Conclusion: A Long-Term Vision for Ethereum
In conclusion, while the immediate prospect of Ethereum breaching $5,000 may be tempered by current algorithmic projections, the long-term outlook remains cautiously optimistic. The data suggests that the path to significant price milestones for ETH is likely to be a gradual ascent, characterized by sustained development, increasing utility, and a maturing market. The projected timelines from platforms like CoinCodex serve as valuable indicators, urging investors to adopt a long-term perspective and to focus on the fundamental strengths and ongoing evolution of the Ethereum network rather than succumbing to short-term speculative exuberance. The journey to $5,000 and beyond will undoubtedly be a testament to Ethereum’s resilience, innovation, and its enduring role in shaping the future of decentralized technologies.









{kind=link}