
The landscape of artificial intelligence is undergoing a significant transformation, driven by advancements in large language models (LLMs) and the increasing demand for privacy-preserving, local AI solutions. This article delves into the practical implementation of a local, privacy-first tool-calling agent, leveraging the recently released Gemma 4 model family from Google and the accessible local inference runtime, Ollama. This development marks a pivotal moment, enabling machine learning practitioners to construct sophisticated, interactive AI systems that operate entirely offline, offering unparalleled control over data and infrastructure.
The core objective of this initiative is to demonstrate how to build an intelligent agent capable of interacting with real-world information sources and executing complex workflows through programmatic tools, all while maintaining strict data privacy by operating on local hardware. The methodology outlined utilizes the lightweight yet powerful gemma4:e2b variant, a model specifically optimized for edge devices, ensuring efficient performance without requiring high-end computational resources.
The Strategic Release of Gemma 4: Empowering Local AI
Google’s introduction of the Gemma 4 model family represents a strategic shift in the open-weights model ecosystem. Unveiled with the intention of democratizing access to frontier-level AI capabilities, Gemma 4 models are released under a permissive Apache 2.0 license. This license is crucial, as it grants developers and enterprises the freedom to use, modify, and distribute the models for virtually any purpose, including commercial applications, without stringent proprietary restrictions. This move by Google is widely seen as a response to the growing demand for open-source alternatives to proprietary models, fostering innovation and allowing for greater transparency and customization in AI development.
The Gemma 4 family encompasses a range of variants, from the parameter-dense 31B and structurally complex 26B Mixture of Experts (MoE) models, designed for high-performance applications, to the more compact, edge-focused variants like gemma4:e2b. This diverse offering ensures that developers can select a model tailored to their specific resource constraints and performance requirements. A key feature across the family, and particularly significant for agentic workflows, is the native support for tool calling. These models have been meticulously fine-tuned to reliably generate structured JSON outputs, enabling them to invoke external functions based on system instructions. This capability transforms them from mere conversational engines into practical systems capable of executing dynamic workflows and interfacing with external APIs in a controlled, local environment.
The implications of such open-weight, capable models are profound. They reduce reliance on cloud-based API services, mitigating concerns around data egress, latency, and recurring costs. For industries with stringent data governance requirements, such as healthcare, finance, and government, local execution provides an indispensable layer of security and compliance.
Demystifying Tool Calling in Language Models
Historically, language models operated as self-contained conversationalists. Their knowledge was limited to the data they were trained on, making them inherently static. If a user inquired about real-time information, such as current weather conditions, live stock prices, or recent news, a traditional LLM could only apologize for its inability to access such data or, worse, generate plausible but entirely fabricated (hallucinated) responses. This fundamental limitation severely restricted their utility in dynamic, real-world applications.
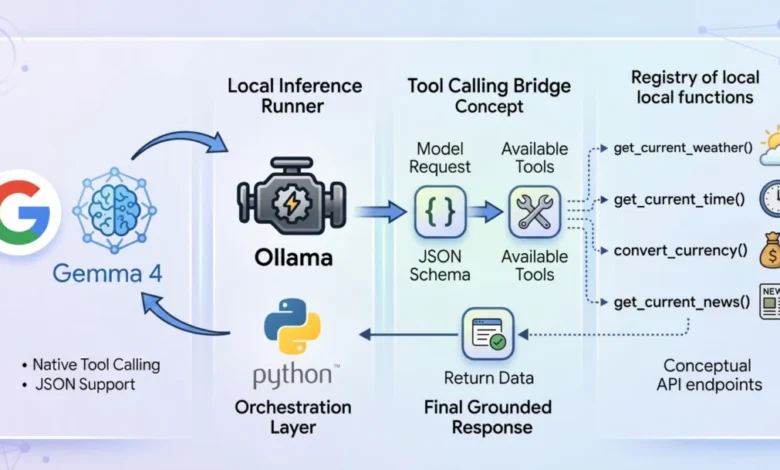
Tool calling, also known as function calling, emerges as the foundational architectural shift designed to bridge this critical gap. It transforms static models into dynamic, autonomous agents by providing them with the ability to interact with external systems and data sources. At its core, tool calling enables an LLM to evaluate a user’s prompt against a predefined registry of available programmatic tools. This registry is typically supplied to the model in a structured format, such as JSON schema, which explicitly defines the tool’s name, purpose, and the parameters it expects.
When tool calling is enabled, the model, instead of attempting to answer a query solely based on its internal weights, intelligently recognizes that an external function is required. It then pauses its inference process, formats a structured request (a "tool call") specifically designed to trigger the appropriate external function, and awaits the result. This request adheres to the specified JSON schema, ensuring that the function receives valid and expected arguments. Once the host application processes this request, executes the external function, and returns the live data, this new context is injected back into the model’s conversational flow. The model then synthesizes this real-time information with its existing knowledge to formulate a grounded, accurate, and contextually relevant final response. This multi-turn interaction is what empowers LLMs to move beyond mere text generation to become proactive problem-solvers.
The Synergy: Ollama and Gemma 4:E2B for Local Inference
To construct a genuinely local, privacy-first tool-calling system, the synergy between Ollama and the gemma4:e2b model is paramount. Ollama serves as the local inference runner, providing an incredibly user-friendly platform for deploying and managing open-source LLMs on consumer-grade hardware. Its ease of setup and robust command-line interface have made it a favorite among developers looking to experiment with local AI without the complexities of manual environment configuration.
The gemma4:e2b (Edge 2 billion parameter) model is a standout choice for this application. It is specifically engineered for resource-constrained environments like mobile devices and IoT applications. This model represents a paradigm shift in what is achievable on consumer hardware, activating an effective 2 billion parameter footprint during inference. This optimization is critical, as it significantly preserves system memory and minimizes computational overhead, leading to near-zero latency execution. By operating entirely offline, gemma4:e2b eliminates rate limits and API costs associated with cloud services, while simultaneously enforcing strict data privacy, as all processing occurs on the user’s local machine.
Despite its incredibly compact size, Google has successfully engineered gemma4:e2b to inherit the advanced multimodal properties and native function-calling capabilities of its larger 31B counterpart. This makes it an ideal foundation for building fast, responsive desktop agents. Furthermore, its efficiency means that developers can test and deploy the capabilities of the new Gemma 4 model family without necessarily requiring a high-end Graphics Processing Unit (GPU), making advanced AI development accessible to a broader audience. The combination of Ollama’s streamlined local deployment and gemma4:e2b‘s optimized performance provides a powerful, private, and cost-effective platform for agentic AI.
Architecting the Agent: A Deep Dive into Implementation
The design philosophy underpinning the agent’s implementation prioritizes a zero-dependency approach, leveraging only standard Python libraries such as urllib for network requests and json for data serialization. This deliberate choice ensures maximum portability and transparency, minimizing "dependency bloat" and making the solution easy to understand, maintain, and deploy across various environments. The complete code for this tutorial is readily available at a public GitHub repository, encouraging experimentation and further development.
The architectural flow of the application operates as a carefully orchestrated loop, mimicking a typical agentic reasoning process:
- User Query Reception: The agent receives a user’s natural language query.
- Initial Model Inference: The user query, along with a registry of available tools (formatted as JSON schema), is sent to the
gemma4:e2bmodel via the Ollama API. - Tool Call Detection: The model processes the input. If it determines that a tool is required to fulfill the request, it generates a structured
tool_callsdictionary within its response, specifying the function name and its required arguments. - Tool Execution: The host application intercepts the
tool_callsdictionary. It dynamically identifies the requested Python function from its internal mapping and executes it, passing the arguments provided by the model. - Result Injection: The output from the executed tool (e.g., weather data, currency conversion) is then formatted as a "tool" role message and appended to the ongoing conversational history.
- Secondary Model Inference: The entire updated message history, now including the result of the tool execution, is sent back to the
gemma4:e2bmodel. - Final Response Generation: With the real-time data now part of its context, the model synthesizes this information and generates a comprehensive, human-readable final response to the user.
This iterative process is crucial, as it allows the LLM to move beyond its initial inference and ground its final output in externally acquired, factual data, effectively eliminating hallucinations for real-time information queries.
Building Practical Tools: The get_current_weather Function
The efficacy of an agent hinges on the quality and utility of its underlying functions. Let’s examine the get_current_weather function, which queries the open-source Open-Meteo API to retrieve real-time weather data for a specified location.
def get_current_weather(city: str, unit: str = "celsius") -> str:
"""Gets the current temperature for a given city using open-meteo API."""
try:
# Geocode the city to get latitude and longitude
geo_url = f"https://geocoding-api.open-meteo.com/v1/search?name=urllib.parse.quote(city)&count=1"
geo_req = urllib.request.Request(geo_url, headers='User-Agent': 'Gemma4ToolCalling/1.0')
with urllib.request.urlopen(geo_req) as response:
geo_data = json.loads(response.read().decode('utf-8'))
if "results" not in geo_data or not geo_data["results"]:
return f"Could not find coordinates for city: city."
location = geo_data["results"][0]
lat = location["latitude"]
lon = location["longitude"]
country = location.get("country", "")
# Fetch the weather
temp_unit = "fahrenheit" if unit.lower() == "fahrenheit" else "celsius"
weather_url = f"https://api.open-meteo.com/v1/forecast?latitude=lat&longitude=lon¤t=temperature_2m,wind_speed_10m&temperature_unit=temp_unit"
weather_req = urllib.request.Request(weather_url, headers='User-Agent': 'Gemma4ToolCalling/1.0')
with urllib.request.urlopen(weather_req) as response:
weather_data = json.loads(response.read().decode('utf-8'))
if "current" in weather_data:
current = weather_data["current"]
temp = current["temperature_2m"]
wind = current["wind_speed_10m"]
temp_unit_str = weather_data["current_units"]["temperature_2m"]
wind_unit_str = weather_data["current_units"]["wind_speed_10m"]
return f"The current weather in city.title() (country) is temptemp_unit_str with wind speeds of windwind_unit_str."
else:
return f"Weather data for city is unavailable from the API."
except Exception as e:
return f"Error fetching weather for city: e"This Python function implements a robust two-stage API resolution pattern. Recognizing that many weather APIs require precise geographical coordinates, the function first transparently intercepts the city string provided by the model and utilizes a geocoding API to resolve it into latitude and longitude coordinates. With these coordinates, it then invokes the Open-Meteo weather forecast endpoint, specifying the desired temperature unit. Finally, it constructs a concise natural language string, presenting the telemetry point to the user. Error handling is integrated to manage cases where city coordinates cannot be found or weather data is unavailable.
However, merely writing the Python function is only half the battle. The LLM needs to be explicitly informed about this tool and its operational parameters. This is achieved by mapping the Python function into an Ollama-compliant JSON schema dictionary, which acts as a contract between the model and the external tool:
"type": "function",
"function":
"name": "get_current_weather",
"description": "Gets the current temperature for a given city.",
"parameters":
"type": "object",
"properties":
"city":
"type": "string",
"description": "The city name, e.g. Tokyo"
,
"unit":
"type": "string",
"enum": ["celsius", "fahrenheit"]
,
"required": ["city"]
This rigid structural blueprint is paramount for reliable tool calling. It explicitly details the expected variable types (string), strict string enumerations ("enum": ["celsius", "fahrenheit"]), and required parameters ("required": ["city"]). This precise definition guides the gemma4:e2b weights, ensuring that the model reliably generates syntax-perfect tool calls that the host application can seamlessly parse and execute.
The Orchestration Engine: How Tool Calls Are Executed
The autonomous workflow’s core resides within the main loop orchestrator. Upon receiving a user’s prompt, an initial JSON payload is constructed for the Ollama API. This payload explicitly links the gemma4:e2b model, includes the current conversational messages history, and critically, appends the global array containing our parsed toolkit (the JSON schemas).
# Initial payload to the model
messages = ["role": "user", "content": user_query]
payload =
"model": "gemma4:e2b",
"messages": messages,
"tools": available_tools, # This is the crucial part
"stream": False
try:
response_data = call_ollama(payload)
except Exception as e:
print(f"Error calling Ollama API: e")
return
message = response_data.get("message", )Once the initial web request resolves, the system critically evaluates the architecture of the returned message block. The process does not blindly assume text generation. Instead, the model, being aware of the active tools, signals its desired outcome by attaching a tool_calls dictionary if it determines that an external function is necessary to fulfill the user’s request.
If tool_calls are present in the message, the standard synthesis workflow is paused. The requested function name and its arguments (kwargs) are parsed dynamically from the dictionary block. The corresponding Python tool is then executed with these parsed arguments. The returned live data from the tool’s execution is subsequently injected back into the conversational array as a new message with the "tool" role.
# Check if the model decided to call tools
if "tool_calls" in message and message["tool_calls"]:
# Add the model's tool calls to the chat history
messages.append(message)
# Execute each tool call
for tool_call in message["tool_calls"]:
function_name = tool_call["function"]["name"]
arguments = tool_call["function"]["arguments"]
if function_name in TOOL_FUNCTIONS: # TOOL_FUNCTIONS is a mapping of names to Python functions
func = TOOL_FUNCTIONS[function_name]
try:
# Execute the underlying Python function
result = func(**arguments)
# Add the tool response to messages history
messages.append(
"role": "tool",
"content": str(result),
"name": function_name
)
except TypeError as e:
print(f"Error calling function: e")
else:
print(f"Unknown function: function_name")
# Send the tool results back to the model to get the final answer
payload["messages"] = messages
try:
final_response_data = call_ollama(payload)
print("[RESPONSE]")
print(final_response_data.get("message", ).get("content", "") + "n")
except Exception as e:
print(f"Error calling Ollama API for final response: e")This snippet highlights the critical secondary interaction. Once the dynamic result from the tool is appended to the messages history with a "tool" role, the entire messages history is bundled up a second time and sent back to the Ollama API. This second pass is fundamental, as it allows the gemma4:e2b reasoning engine to read and comprehend the real-time telemetry strings it previously triggered, thereby bridging the final gap to output the data logically and in human terms. This multi-turn, feedback-loop mechanism is what enables the agent to provide grounded, factual responses based on live external data.
Expanding Agent Capabilities: Additional Tools and Modularity
With the robust architectural foundation firmly established, enriching the agent’s capabilities becomes a modular and straightforward process. The "zero-dependency" philosophy and the clear JSON schema definitions mean that adding new functionalities requires nothing more than developing new Python functions and their corresponding schema mappings. This approach significantly enhances the agent’s utility without introducing external orchestration complexities or heavy dependencies.
For instance, the article expands the agent’s toolkit by incorporating three additional live tools, each processed through the identical JSON schema registry methodology:
convert_currency: This function would likely interface with a real-time currency exchange rate API. Its JSON schema would define parameters foramount,from_currency, andto_currency, allowing the model to dynamically convert values.get_current_time: This tool would query a time-zone-aware API to provide the current time for a specified city or geographical coordinate. Its schema would primarily require acityortimezoneparameter.get_latest_news: This function would connect to a news API, fetching recent headlines or articles based on a givenqueryortopic. The schema would define the search parameter, allowing the model to retrieve relevant information.
Each new capability, once defined in Python and its JSON schema, is simply added to the available_tools array passed to the Ollama API. This modularity is a testament to the elegant design of tool calling, allowing for continuous expansion of the baseline model’s utility and transforming it into a versatile, multi-functional agent.
Demonstrating Efficacy: Testing the Agent’s Prowess
The true test of any AI agent lies in its performance under varied conditions. The article showcases the agent’s capabilities through several test queries, demonstrating its reliability and accuracy, even with a relatively compact model like gemma4:e2b.
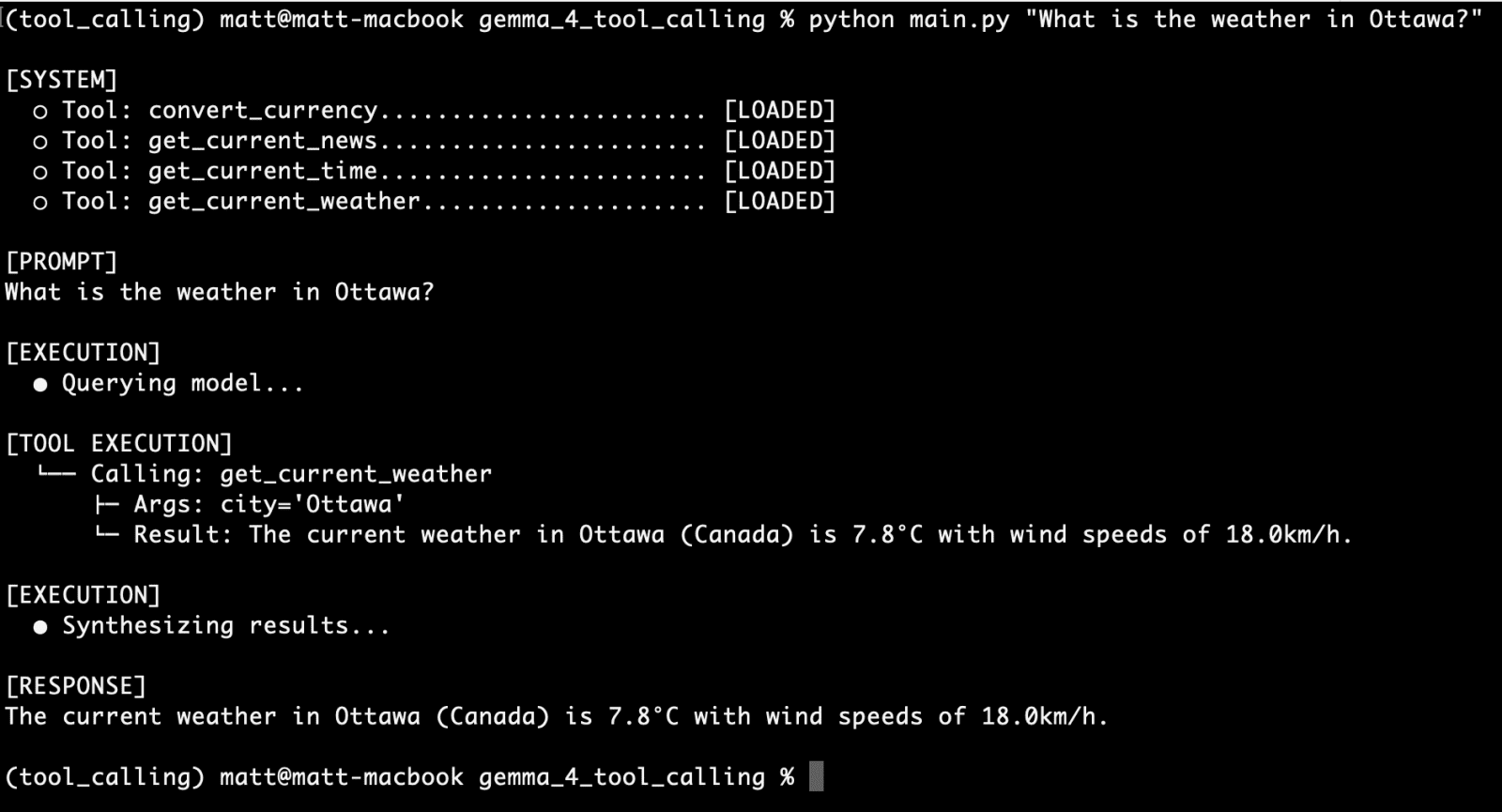
Consider the initial query for the get_current_weather function:
"What is the weather in Ottawa?"
The command-line interface output clearly demonstrates the agent’s successful execution: it first identifies the need for the get_current_weather tool, calls it with "Ottawa" as the city parameter, retrieves the live weather data, and then synthesizes this information into a coherent response. This successful first run validates the core tool-calling mechanism.
Next, testing another tool independently, convert_currency:
"Given the current currency exchange rate, how much is 1200 Canadian dollars in euros?"
Again, the agent accurately identifies the convert_currency tool, extracts the amount and currency parameters, executes the conversion, and presents the precise euro equivalent. This further confirms the agent’s ability to selectively invoke and leverage specific tools based on the user’s intent.
The ultimate challenge comes with stacking multiple tool-calling requests within a single, complex prompt, especially considering the agent is powered by a 4 billion parameter model that utilizes only half its parameters during inference:
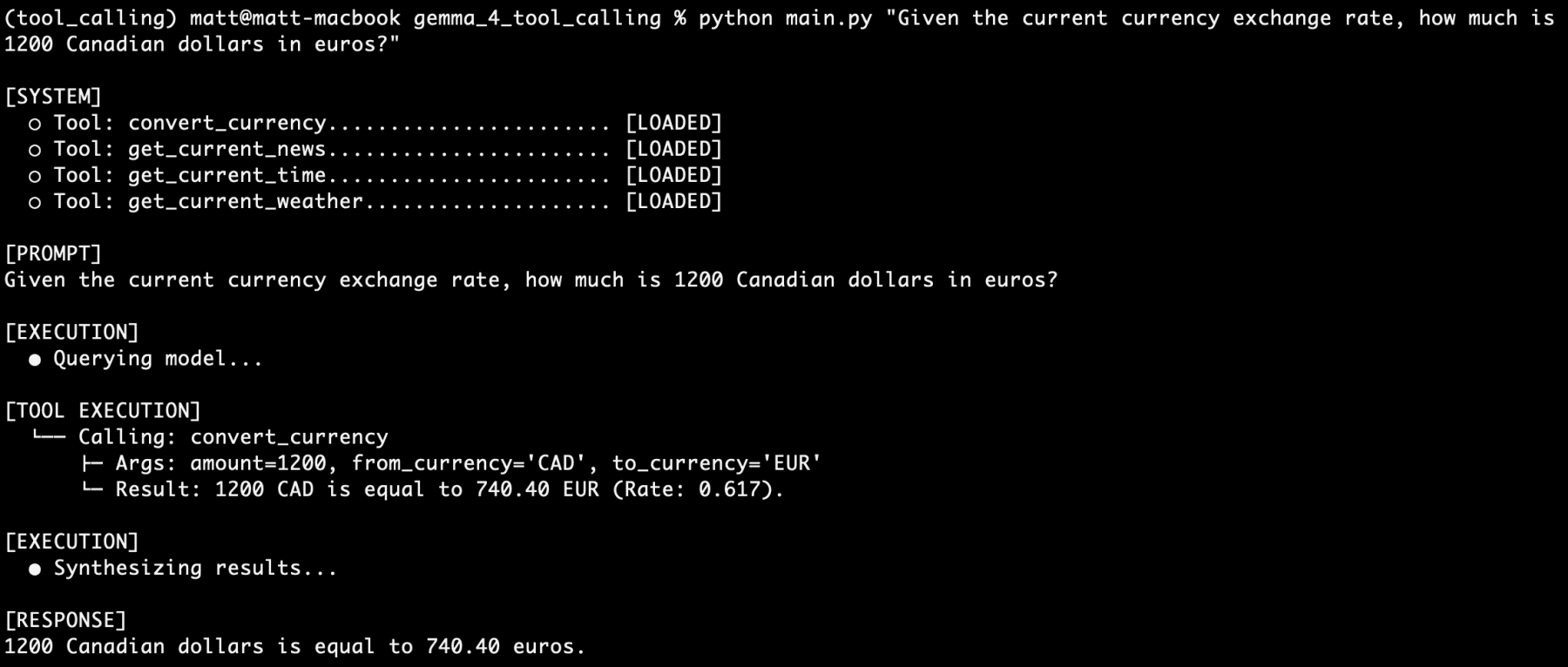
"I am going to France next week. What is the current time in Paris? How many euros would 1500 Canadian dollars be? what is the current weather there? what is the latest news about Paris?"
The results are striking. The command-line interface output displays a sequence of four distinct tool calls: one for get_current_time, one for convert_currency, one for get_current_weather, and one for get_latest_news. Each function is correctly identified, parameters are accurately extracted, the tools are executed sequentially, and their respective results are fed back into the model. Finally, the gemma4:e2b model synthesizes all this disparate information into a single, comprehensive, and contextually rich response.
This impressive demonstration underscores the gemma4:e2b model’s robust reasoning engine and its highly reliable tool-calling capabilities. Anecdotal testing over a prolonged period, encompassing hundreds of prompts with varying degrees of vagueness, reportedly failed to stump the model within the scope of its defined tools. This consistent performance, especially from a local, edge-optimized model, highlights the significant progress in making advanced agentic AI accessible and dependable on consumer hardware.
Broader Implications and the Future of Edge AI
The advent of native tool-calling behavior within open-weight models like Gemma 4, combined with efficient local inference solutions like Ollama, represents one of the most practical and impactful developments in local AI to date. This technological confluence unlocks a myriad of possibilities across various sectors.
Enhanced Privacy and Security: By enabling AI systems to operate securely offline, sensitive data can remain entirely on local devices, eliminating the risks associated with cloud data transfers and storage. This is particularly critical for industries dealing with confidential information, individual users concerned about their personal data, and sovereign entities requiring data residency.
Cost Reduction and Accessibility: Developers and organizations can significantly reduce or eliminate recurring API costs and cloud infrastructure expenses. This democratization of advanced AI makes sophisticated agentic capabilities accessible to a broader range of users, including hobbyists, small businesses, and researchers who might otherwise be constrained by budgetary limitations. The ability to run powerful models without high-end GPUs further lowers the barrier to entry.
Increased Reliability and Autonomy: Local execution removes dependencies on internet connectivity, ensuring that agents can operate reliably even in disconnected or intermittent network environments. This fosters the development of truly autonomous systems that are not subject to external service outages or rate limits.
Rapid Innovation and Customization: The open-source nature of Gemma 4, coupled with the ease of tool integration, accelerates innovation. Developers can rapidly prototype, test, and deploy highly customized agents tailored to specific tasks or domains, integrating with proprietary local systems or unique datasets without vendor lock-in.
The Future of Agentic Systems: Architecturally integrating direct access to the web, local file systems, raw data processing logic, and localized APIs through tool calling empowers even low-powered consumer devices to operate autonomously in ways previously restricted exclusively to cloud-tier hardware. This paves the way for a new generation of intelligent assistants, smart home devices, and specialized professional tools that can actively retrieve information, perform actions, and interact with the physical and digital world in a grounded and intelligent manner.
In conclusion, the successful demonstration of a local, privacy-first tool-calling agent using Gemma 4 and Ollama signifies a monumental leap towards practical, accessible, and ethical AI. This framework empowers developers to build complex, responsive, and secure agentic systems that operate at the edge, heralding a future where advanced AI capabilities are not just powerful, but also private, pervasive, and within everyone’s reach. The next logical step, and one eagerly anticipated, is the development of fully agentic systems that leverage these foundational capabilities to achieve even greater levels of autonomy and utility.


{kind=link}