
Microsoft Releases Record-Shattering 570+ Security Fixes in July Patch Tuesday, Citing AI-Accelerated Vulnerability Discovery

Microsoft Corp. today released an unprecedented volume of software updates, addressing at least 570 security vulnerabilities across its Windows operating systems and other software. This staggering figure nearly triples the number of fixes from last month’s already record-setting Patch Tuesday and underscores a significant shift in the cybersecurity landscape, driven primarily by the burgeoning capabilities of artificial intelligence in discovering system weaknesses. The sheer scale of this month’s patches highlights both an intensified focus on security by Microsoft and the accelerated pace of vulnerability identification in the era of AI.
The Unprecedented Scope of July 2026 Patch Tuesday
The July 2026 Patch Tuesday stands out as one of the most extensive security releases in Microsoft’s history, with a total of 570 vulnerabilities mitigated. This massive overhaul impacts a wide array of Microsoft products, including various iterations of Windows, Microsoft Office, Azure, Edge, SharePoint, BitLocker, Active Directory Federation Services, and even the increasingly prominent Microsoft Copilot. Among the hundreds of resolved issues, nearly 60 were designated with a "critical" severity rating. Critical vulnerabilities are those that, if exploited, could allow malicious actors or malware to gain remote control over a Windows device with minimal or no user interaction, posing an immediate and severe threat to system integrity and data confidentiality.
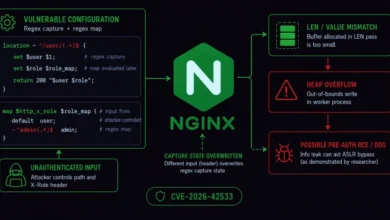
Beyond the critical fixes, Microsoft also took urgent action on three zero-day flaws. Zero-day vulnerabilities are particularly dangerous as they are known to attackers before a patch is publicly available, meaning they are actively being exploited "in the wild." Two of these zero-day weaknesses specifically allowed for an "elevation of privilege" on a Windows system, enabling an attacker to gain higher access rights than initially permitted. These include CVE-2026-56155, an Active Directory Federation Services bug, and CVE-2026-56164, a vulnerability within Microsoft SharePoint. The third zero-day, CVE-2026-50661, was identified as a security feature bypass in Windows BitLocker. This flaw could potentially grant attackers access to encrypted data if they manage to obtain physical access to the device. While Microsoft confirmed that this bug had been publicly detailed, it stated it was not aware of active exploitation, though its inclusion as a zero-day underscores its perceived risk.
AI: The Dual-Edged Sword of Vulnerability Discovery
A key revelation accompanying this colossal patch release is Microsoft’s explicit attribution of the surging vulnerability counts to the assistance of artificial intelligence. Pavan Davuluri, Microsoft’s Executive Vice President, articulated this shift in a blog post on July 9, anticipating that Windows users would observe "a higher volume of security updates included in each security release." Davuluri elaborated, stating, "The pace of vulnerability discovery is changing with advances in AI making it possible to find more issues, faster, across more code, with new mechanisms that can accelerate both discovery and analysis."
This statement signals a fundamental change in how software vulnerabilities are identified. AI-powered tools can sift through vast quantities of code, detect complex patterns, and even predict potential weaknesses far more efficiently than human researchers alone. While this accelerated discovery by AI is a boon for defenders, allowing for quicker identification and patching, it simultaneously presents a formidable challenge. The same AI capabilities that assist in finding flaws can also be leveraged by malicious actors to expedite the creation of sophisticated exploits for known vulnerabilities. This creates an ongoing "AI arms race" where the speed of defense must continually match or exceed the speed of offense.
One notable vulnerability highlighted by Jack Bicer, director of vulnerability research at Action1, was CVE-2026-48561. This remote code execution (RCE) flaw in Microsoft Copilot, boasting a high CVSS (Common Vulnerability Scoring System) threat score of 9.6, demonstrates the evolving attack surface. The vulnerability could allow an unauthorized attacker to execute code over the network. Microsoft detailed a potential exploitation vector where an attacker could host a malicious website designed to cause Microsoft Edge for Android to automatically send crafted prompts to Copilot when a user visits the site, leading to code execution. This scenario underscores the increasing complexity of attacks that bridge different software components and platforms, with AI-driven assistants becoming new potential targets.
The Evolving Challenge to Exploitability Assessments
The rapid evolution of AI in cybersecurity also necessitates a reevaluation of traditional methods for assessing exploitability. Microsoft has historically used an "exploitability index" to provide its best estimate of how likely attackers are to develop reliable exploits for a given vulnerability. However, this human-centric assessment is increasingly outpaced by machine capabilities.
Satnam Narang, a senior staff research engineer at Tenable, critically observed that Microsoft’s exploitability index struggles to adapt to the "machine speed of discovery." He pointed to a telling example: Microsoft initially rated this month’s SharePoint zero-day (CVE-2026-56164) as "less likely" to be exploited. Yet, the Cybersecurity and Infrastructure Security Agency (CISA) added this very flaw to its Known Exploited Vulnerabilities (KEV) catalog on July 1, indicating active exploitation. This discrepancy highlights a growing chasm between traditional risk assessment and the reality of the threat landscape.
Narang further substantiated his argument by citing findings from Anthropic’s Red Team. Their research, involving the Mythos Preview AI model, demonstrated the fragility of current exploitability predictions. The model successfully produced proof-of-concept exploits for 13 out of 14 vulnerabilities that Microsoft had rated as "Exploitation Less Likely" or "Exploitation Unlikely." "What this means is that our way of looking at Patch Tuesday has changed, because the exploitability index is centered around humans, not AI tools, and as these tools continue to improve, defense needs to improve alongside it," Narang emphasized. This suggests that the cybersecurity industry, including vendors like Microsoft, must develop more dynamic and AI-informed methods for predicting and prioritizing threats, moving beyond human intuition to embrace machine-speed analysis.
Industry-Wide Implications and Accelerating Patch Cadence
The record-breaking patch numbers from Microsoft are not an isolated incident but rather indicative of a broader industry trend. Chris Goettl, a cybersecurity expert at Ivanti, noted that several other major software developers are also increasing their patch cadences. Adobe, for instance, announced a move to twice-monthly security bulletins, to be published on the second and fourth Tuesdays of each month, also citing AI as a factor in accelerating their patch cycles. Companies like Cisco, Mozilla, and Oracle are similarly shipping updates more frequently. Google’s June 2026 patch batches alone included over 900 security fixes, further illustrating the pervasive nature of this trend.
This acceleration across the industry points to a shared understanding among technology giants: the threat landscape is evolving at an unprecedented rate, largely fueled by AI. The increasing frequency and volume of patches put immense pressure on IT departments and individual users alike. For IT professionals managing large enterprise networks, the traditional monthly Patch Tuesday rhythm is becoming a relic of the past, replaced by a continuous, demanding cycle of vulnerability assessment, testing, and deployment.
Practical Advice for Users and IT Professionals
Given the colossal volume of patches released this month, and the inherent risks associated with such widespread updates, cybersecurity experts are reiterating best practices for end-users and IT administrators. A fundamental recommendation is to always back up your Windows system and critical data before applying major operating system updates. This precautionary measure can mitigate potential data loss or system instability should an unforeseen issue arise during or after the patching process.
Furthermore, for end-users, it may be prudent to wait a few days before immediately applying these fixes. It is not uncommon for security patches, especially those of this magnitude, to inadvertently introduce system stability issues or compatibility problems with existing software or hardware configurations. Delaying application by a few days allows early adopters to identify and report such issues, giving Microsoft and the community time to address them or for users to find workarounds before they are impacted. The probability of encountering such issues arguably increases significantly with a patch count as gigantic as the one released today.
For IT departments, this Patch Tuesday presents a heightened challenge. The sheer number of fixes necessitates meticulous planning, rigorous testing in controlled environments, and a phased rollout strategy. Robust patch management solutions capable of automating much of this process, while also providing granular control and reporting, are no longer a luxury but a necessity. The focus must shift from merely applying patches to strategically managing the entire lifecycle of vulnerability remediation, from discovery to verified deployment.
The Future of Cybersecurity: An AI-Driven Arms Race
The July 2026 Patch Tuesday serves as a stark reminder of the dynamic and increasingly complex nature of cybersecurity. The integration of AI into both vulnerability discovery and exploit generation marks a new era, demanding adaptive strategies from both defenders and attackers. As AI tools continue to improve, the speed at which vulnerabilities are found and weaponized will only accelerate.
This ongoing "AI arms race" necessitates continuous innovation in defensive technologies, including AI-powered threat detection, automated response systems, and more sophisticated vulnerability management platforms. It also calls for a shift in mindset, moving beyond reactive patching to proactive security postures that anticipate threats and integrate intelligence from emerging AI capabilities. The cybersecurity community, from software vendors to individual users, must remain vigilant and agile to navigate this rapidly evolving landscape, ensuring that the benefits of AI in security outweigh its potential for exploitation. The path forward will undoubtedly be characterized by an incessant cycle of discovery, remediation, and adaptation, with AI at its very core.






{kind=link}