
The Future of Human Knowledge The Semantic Web
The future of human knowledge the semantic web – The future of human knowledge: the semantic web promises a revolutionary shift in how we acquire, store, and access information. This interconnected web of data, built on logic and meaning, could transform education, research, and countless other fields. Imagine a world where information is not just linked, but understood, allowing for far more nuanced and effective searches and discoveries.
This Artikel explores the core concepts, potential applications, and challenges of this transformative technology, detailing how the semantic web will redefine our relationship with knowledge. It delves into the technical aspects, including data structures, ontologies, and knowledge graphs, while also highlighting ethical considerations and practical limitations.
Defining the Semantic Web
The World Wide Web, as we know it, is fundamentally a collection of documents linked by hypertext. This structure, while enabling vast information access, lacks a true understanding of the meaning behind the words and data. The Semantic Web aims to address this limitation by adding a layer of meaning and logic to the web, enabling computers to understand and process information in a way that’s closer to how humans do.The current web primarily focuses on presenting information, whereas the Semantic Web aims to represent the meaning and relationships between that information.
This crucial distinction unlocks a world of possibilities for automated reasoning, knowledge discovery, and intelligent applications. Think of it as upgrading from a simple dictionary to a sophisticated encyclopedia with cross-references and logical connections between entries.
The Semantic Web: A Deeper Understanding
The Semantic Web is an extension of the current web that aims to make data understandable by computers. It does this by adding metadata and logic to the data, enabling computers to process information more effectively. This differs significantly from the current web, which primarily focuses on displaying information in a user-friendly way, without explicitly defining its meaning.
Core Principles of the Semantic Web
The Semantic Web relies on several core principles to achieve its goals:
- Linked Data: Data is represented in a way that allows it to be linked to other data, creating a network of interconnected information. This allows computers to follow these connections and draw inferences about the relationships between different pieces of data.
- Semantic Description: Data is described using formal ontologies, which define concepts and their relationships. These ontologies provide a shared vocabulary that allows different systems to understand the same information in the same way. This is crucial for avoiding ambiguity and ensuring consistent interpretation.
- Automated Reasoning: The Semantic Web allows computers to automatically reason about the meaning of data. This enables them to draw conclusions and make inferences based on the relationships between different pieces of data. For instance, if a system knows that “John is the father of Mary” and “Mary is the mother of Susan,” it can deduce that “John is the grandfather of Susan.”
Technologies Behind the Semantic Web
Several key technologies support the Semantic Web, enabling the representation and manipulation of meaningful data:
- Resource Description Framework (RDF): A framework for representing information in the form of statements about resources. It defines a common way to describe data, allowing different systems to exchange information seamlessly. RDF uses triples, consisting of subject, predicate, and object to create these statements.
- Web Ontology Language (OWL): A language for representing ontologies. It provides a structured way to define concepts and their relationships, allowing computers to reason about the meaning of data. OWL builds upon RDF, providing more expressive power for defining complex relationships and knowledge.
- SPARQL: A query language for RDF data. It allows users to retrieve and manipulate information stored in RDF graphs. SPARQL queries are used to ask questions about the data, much like SQL queries are used to ask questions about relational databases.
Current Web vs. Semantic Web
| Feature | Current Web | Semantic Web |
|---|---|---|
| Data Representation | Mainly text and images, lacking explicit meaning. | Data represented using ontologies and RDF, providing explicit meaning and relationships. |
| Data Interpretation | Interpreted by humans based on context. | Interpreted by computers through automated reasoning. |
| Data Linking | Limited linking between documents based on s or hyperlinks. | Extensive linking using ontologies and RDF, enabling knowledge graphs. |
| Scalability | Relatively easy to scale for information presentation. | Requires more sophisticated infrastructure to manage large amounts of linked data. |
| Automation | Limited automation in data processing and analysis. | High potential for automation in data processing, knowledge discovery, and decision-making. |
The Future of Human Knowledge
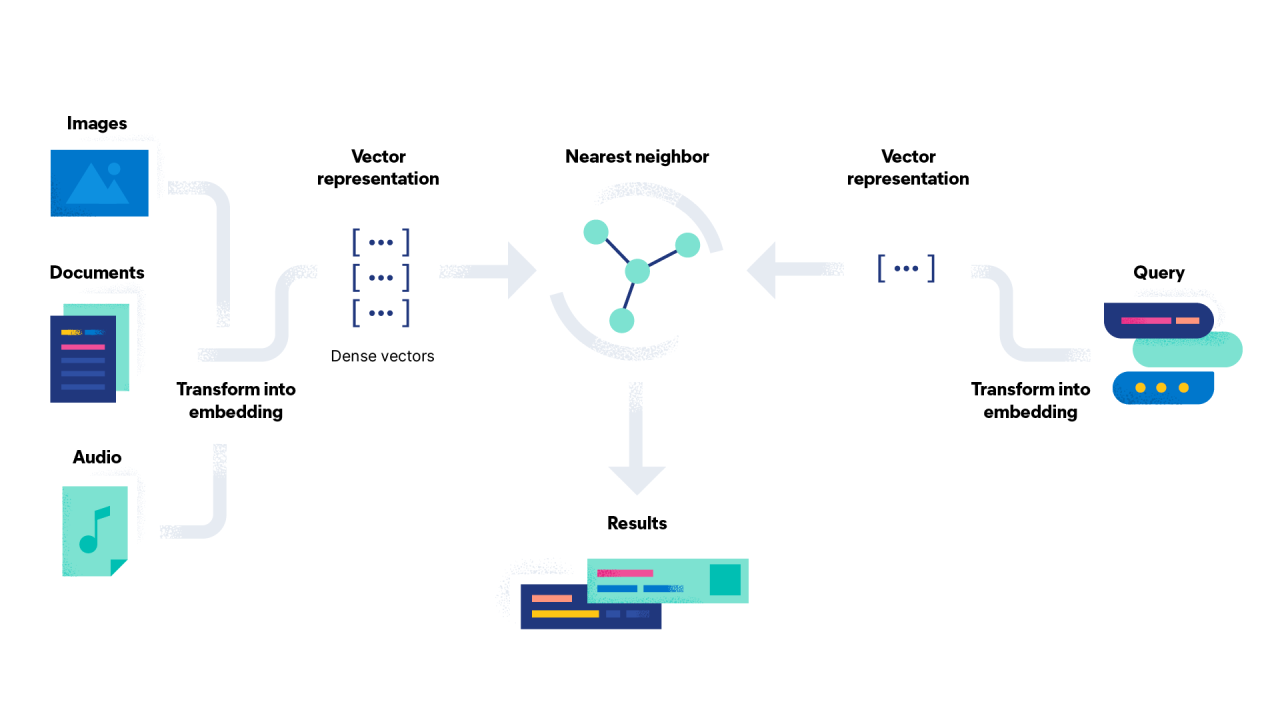
The Semantic Web promises a paradigm shift in how humans interact with and utilize knowledge. It’s not merely about accumulating more data, but about structuring it in a way that computers can understand and utilize, enabling sophisticated analysis and new forms of knowledge discovery. This interconnected, machine-readable knowledge base will fundamentally alter how we learn, research, and conduct business.The Semantic Web, by connecting data in a meaningful way, enables a level of understanding and analysis previously unimaginable.
The future of human knowledge, the semantic web, promises a connected, easily accessible repository of information. However, the recent legislation criminalizing file sharing, like the new bill making file swapping a felony here , raises concerns about controlling the flow of knowledge. These restrictions could severely hamper the development of a truly open and democratic semantic web.
We need to consider the long-term implications of such laws on the future of information access.
This interconnectedness allows for the identification of patterns and relationships within vast datasets, fostering a deeper understanding of complex phenomena and accelerating research progress. Think of it as building a vast, interconnected library where books aren’t just stored, but their contents are understood and linked to other relevant information.
Impact on Knowledge Acquisition, Storage, and Access
The Semantic Web will fundamentally reshape how humans acquire, store, and access knowledge. Instead of searching through unstructured data, users will query and retrieve information based on meaning and relationships. This semantic approach to information retrieval will lead to more precise and relevant results, empowering users to find the exact knowledge they need, rapidly. Users will be able to explore connections and relationships between concepts and data points in a way that is intuitive and effortless, fostering a richer understanding of the subject matter.
This will enhance knowledge acquisition by making it easier to connect fragmented pieces of information and develop a more holistic view.
The future of human knowledge, the semantic web, hinges on powerful computational tools. As Moore’s Law slows, we’re looking at innovative solutions like those explored in “life after moores law beyond silicon” life after moores law beyond silicon. These alternative technologies are crucial for scaling knowledge storage and retrieval, ensuring the semantic web can continue to evolve and become more sophisticated in the future.
Transformation of Information Retrieval and Research
The Semantic Web’s ability to understand context and meaning will revolutionize information retrieval and research. Complex queries will be expressed in natural language, and search engines will interpret the intent behind the query to deliver highly relevant results. This is a significant advancement from -based searches, which often return irrelevant or incomplete results. The Semantic Web will enable researchers to easily identify and analyze relationships between different research findings, leading to breakthroughs in areas like scientific discovery, historical analysis, and social science research.
Tools will facilitate the comparison of data from disparate sources, allowing researchers to uncover hidden patterns and connections, leading to new insights.
Improving Education and Learning
The Semantic Web can drastically improve education and learning by providing personalized and adaptable learning experiences. Imagine educational resources organized semantically, allowing students to access information tailored to their individual needs and learning styles. Educational institutions can create dynamic learning environments where students can explore complex topics through interactive simulations and visualizations. Interactive learning tools will be available that dynamically adapt to a student’s learning pace and progress, enabling them to grasp concepts more effectively.
This personalized approach will enhance understanding and retention, making education more engaging and effective.
Potential Benefits in Different Sectors
| Sector | Potential Benefits |
|---|---|
| Education | Personalized learning paths, adaptive assessments, interactive simulations, access to a vast network of knowledge resources. |
| Research | Enhanced data analysis, faster identification of relationships between research findings, improved data integration, reduced duplication of effort. |
| Business | Improved decision-making through data-driven insights, more efficient supply chain management, better customer understanding, enhanced marketing campaigns. |
| Healthcare | Enhanced patient care through access to personalized medical histories, more accurate diagnoses through integration of patient data from various sources, improved drug discovery. |
“The Semantic Web is not about creating a single, monolithic database, but about creating a shared understanding of information.”
Tim Berners-Lee
Data Structures and Representation
The Semantic Web hinges on the ability to represent knowledge in a way that computers can understand and reason with. This involves more than just storing data; it demands a structured approach that allows for connections, inferences, and ultimately, a richer understanding of the information itself. This structured approach relies heavily on specific data structures and representation methods.Different methods of knowledge representation offer varying levels of expressiveness and computational tractability.
The choice of method often depends on the specific application and the complexity of the knowledge being represented. The common thread across these methods is the need for clarity, standardization, and interoperability.
Ontologies and Knowledge Graphs
Ontologies provide structured vocabularies and classifications of concepts, defining relationships between them. They act as blueprints for knowledge representation, defining the types of entities and the relationships between them. Knowledge graphs, on the other hand, are visual representations of these relationships, making the connections and dependencies between different concepts readily apparent. Together, ontologies and knowledge graphs form the backbone of the Semantic Web, enabling computers to understand and reason about the world in a more meaningful way.
They allow for the explicit definition of concepts and the relationships between them, enabling inference and reasoning capabilities.
Data Modeling Languages
Several data modeling languages are used in the Semantic Web to represent knowledge. These languages provide the syntax and semantics for describing entities, properties, and relationships. The choice of language depends on the complexity of the knowledge to be represented and the desired level of expressiveness.
- RDF (Resource Description Framework): RDF is a fundamental language for representing information in the Semantic Web. It provides a way to describe resources, their properties, and the relationships between them. RDF is based on a simple graph structure, making it easy to represent complex knowledge. RDF statements typically follow a subject-predicate-object format, like “The Eiffel Tower is located in Paris.” RDF is widely used because of its simplicity and flexibility.
It’s often used for describing metadata and representing data in a structured format.
- RDF Schema (RDFS): RDFS builds upon RDF by providing a vocabulary for defining classes and properties. It allows for the creation of ontologies, which are formal specifications of concepts and their relationships. RDFS provides a mechanism for defining hierarchies of classes, which helps to organize and structure knowledge. RDFS is an extension of RDF, adding vocabulary to define classes and properties.
It defines concepts and relations between them, allowing for the creation of more complex knowledge structures.
- OWL (Web Ontology Language): OWL is a more expressive language for defining ontologies. It extends RDFS by providing more powerful constructs for defining classes, properties, and relationships. OWL allows for the specification of complex constraints and rules, making it suitable for applications that require sophisticated knowledge representation. OWL provides a way to define ontologies with more complex relationships and constraints, including the ability to define logical axioms and inferences.
Standardized Formats and Vocabularies
Standardized formats and vocabularies are crucial for interoperability in the Semantic Web. They ensure that different systems can exchange and understand data in a consistent manner. This promotes the sharing and reuse of knowledge across different applications and organizations.
- Turtle (Terse RDF Triple Language): A concise syntax for writing RDF data, Turtle offers a human-readable way to express RDF statements. It’s often preferred for its conciseness and ease of parsing.
- SPARQL (SPARQL Protocol and RDF Query Language): A query language for RDF data, SPARQL allows users to retrieve specific information from large datasets. It’s essential for querying and extracting knowledge from knowledge graphs.
Knowledge Representation Formats
Different knowledge representation formats offer varying degrees of expressiveness and complexity. The choice of format depends on the specific needs of the application.
| Format | Description | Example Usage |
|---|---|---|
| RDF/XML | XML-based serialization of RDF data. | Describing metadata about a web page. |
| N-Triples | Plain text format for RDF triples. | Storing RDF data in a database or knowledge graph. |
| Turtle | Concise text format for RDF. | Representing complex knowledge in a web application. |
Challenges and Limitations
The Semantic Web, while promising, faces significant hurdles in its implementation. The sheer scale and complexity of integrating semantic data across diverse sources, coupled with the need for consistent interpretation, present formidable obstacles. Ensuring data quality and interoperability across various systems is crucial for the Semantic Web’s success, but these are not trivial tasks.
Data Quality and Consistency
Maintaining high-quality data is essential for the reliability of the Semantic Web. Inaccurate or incomplete data will inevitably lead to flawed inferences and conclusions. Real-world data often contains errors, inconsistencies, and ambiguities. For example, different databases might use different formats to represent the same concept, leading to difficulties in integrating the data.
- Data Validation and Cleansing: Automated methods for validating and cleansing data are needed to minimize errors and inconsistencies. This involves detecting and correcting inconsistencies in data formats, units, and values.
- Data Governance and Standards: Establishing clear data governance policies and promoting the use of common standards for data representation are crucial. This involves defining clear roles and responsibilities for data management, ensuring consistency in data formats and vocabulary.
- Human-in-the-loop Validation: While automation is beneficial, human intervention is often necessary for complex data validation, especially when dealing with subjective information or interpretations.
Interoperability and Standardization
The Semantic Web’s ability to connect and share information effectively depends heavily on its interoperability. Different systems and databases may use different ontologies, schemas, and vocabularies, making it difficult to combine data from disparate sources.
- Ontology Alignment and Mapping: Matching concepts and terms across different ontologies is crucial for interoperability. This requires developing sophisticated algorithms for aligning and mapping different vocabularies.
- Common Vocabularies and Standards: The widespread adoption of standardized ontologies and vocabularies is essential for facilitating interoperability. Examples include the use of ontologies like schema.org for representing information about web pages.
- Semantic Web Languages: Ensuring widespread support and implementation of semantic web languages like RDF and SPARQL are critical for achieving seamless data exchange and query processing across systems.
Technical and Practical Hurdles
Several technical and practical obstacles hinder the widespread adoption of the Semantic Web. The computational resources needed for processing and reasoning over large amounts of semantic data can be significant.
- Computational Complexity: Reasoning over large amounts of semantic data can be computationally intensive. Efficient algorithms and optimized hardware are needed to handle this complexity.
- Scalability Issues: The Semantic Web needs to be able to scale to handle ever-increasing volumes of data. This requires robust architectures and distributed computing solutions.
- User Adoption and Training: A significant barrier to adoption is the need for users to understand and utilize the Semantic Web technologies. Training programs and educational resources are essential to facilitate user engagement.
Obstacles and Potential Solutions
| Obstacle | Potential Solution |
|---|---|
| Data Quality Issues | Automated validation tools, data cleansing techniques, clear data governance policies |
| Lack of Interoperability | Standardized ontologies, common vocabularies, semantic web languages |
| Computational Complexity | Optimized algorithms, distributed computing, high-performance hardware |
| Limited User Adoption | Training programs, user-friendly interfaces, demonstration projects |
Applications and Use Cases
The Semantic Web, with its ability to represent knowledge in a machine-readable format, opens doors to a vast array of applications across diverse domains. From streamlining healthcare processes to improving financial decision-making, the potential benefits are substantial. This section explores some current and potential use cases, highlighting how Semantic Web technologies are already being implemented and how they can revolutionize various industries.The power of the Semantic Web lies in its ability to connect disparate data sources.
This interconnectedness allows machines to understand the meaning behind data, enabling sophisticated tasks that go beyond simple matching. This section details specific examples and showcases how these technologies can impact different fields.
Current Applications
Semantic Web technologies are already integrated into existing systems and services, often unnoticed by the average user. These technologies provide the underlying framework for tasks that require understanding and reasoning about data, rather than just storing and retrieving it. For instance, many online search engines employ semantic analysis to provide more accurate and contextually relevant results.
The future of human knowledge, the semantic web, promises a revolutionary way to access and process information. But vulnerabilities like those highlighted in the recent latest Windows flaws foretell worm threat remind us that robust security is crucial for any system, even ones designed to handle the vast expanse of data the semantic web will encompass.
This underscores the importance of continuous vigilance and innovation in securing the future of knowledge.
Potential Applications in Healthcare
Semantic Web technologies can significantly improve healthcare by enabling the integration of patient data from various sources. This allows for a holistic view of a patient’s medical history, leading to better diagnosis and treatment planning. For example, a patient’s medical records, test results, and even social determinants of health could be linked and analyzed semantically to identify potential risks or patterns.
Potential Applications in Finance
In finance, the Semantic Web can automate tasks such as fraud detection, risk assessment, and regulatory compliance. By connecting financial data from various sources and applying semantic reasoning, systems can identify suspicious transactions or potential risks more effectively. Furthermore, it can be used for better compliance with regulations and for quicker processing of transactions.
Potential Applications in Government
Government agencies can leverage the Semantic Web to improve public services and streamline administrative processes. Semantic representations of laws, regulations, and citizen data can be used to automate tasks like benefits eligibility checks, public records retrieval, and even disaster response coordination. The integration of semantic data can provide more transparency and efficiency in governmental operations.
Table of Use Cases and Potential Impact
| Use Case | Potential Impact |
|---|---|
| Healthcare: Improved diagnosis and treatment planning | Reduced medical errors, enhanced patient care, better resource allocation. |
| Finance: Automated fraud detection and risk assessment | Increased security, reduced financial losses, improved regulatory compliance. |
| Government: Streamlined public services and administrative processes | Increased efficiency, enhanced transparency, improved citizen engagement. |
| E-commerce: Personalized recommendations and enhanced search results | Improved customer experience, increased sales, enhanced user engagement. |
The Future of Information Access and Retrieval: The Future Of Human Knowledge The Semantic Web
The Semantic Web promises a paradigm shift in how we access and interact with information. Instead of relying on -based searches that often yield irrelevant results, the Semantic Web aims to understand the meaning and relationships between data. This profound change will fundamentally alter how we discover knowledge, making it more efficient and insightful.The Semantic Web’s ability to represent knowledge in a structured, machine-readable format allows for more sophisticated information retrieval.
This semantic understanding, far beyond matching, opens doors to more accurate and relevant search results, enabling us to find what we need with greater precision and speed. This is a crucial step towards a more intelligent and accessible knowledge ecosystem.
Revolutionizing Information Access
The Semantic Web’s potential to revolutionize information access lies in its ability to represent knowledge in a machine-understandable format. This allows computers to grasp the meaning and relationships between data, rather than just relying on s. This semantic understanding will empower search engines to return results that are highly relevant to a user’s needs, even if those needs are expressed in natural language or with complex queries.
Impact on Search Engines and Knowledge Discovery Tools
Search engines will evolve beyond simple matching to become intelligent knowledge assistants. Instead of just returning a list of documents containing s, they will be able to discern the context and relationships between data, providing users with more comprehensive and insightful results. Knowledge discovery tools will also benefit, enabling users to uncover hidden connections and patterns in data that were previously inaccessible.
Imagine a search engine that understands the nuances of a query, not just the words, and delivers results that are not only relevant but also provide the broader context.
Enhancing Information Quality and Trustworthiness
The Semantic Web can enhance information quality and trustworthiness by providing a framework for linking data sources and verifying information. By establishing relationships between different pieces of information, the Semantic Web helps to identify inconsistencies and biases, making it easier to evaluate the reliability of different sources. This structured approach to knowledge representation makes it possible to track the provenance of data and its connections to other data, thus enhancing trust and reducing misinformation.
Potential Semantic Web-Enabled Search Engine Functionalities
The Semantic Web will unlock a wealth of new functionalities for search engines. These include:
- Contextual Search: Search engines can understand the context of a query, not just the s. For example, if a user searches for “best Italian restaurants near me,” the search engine can use location data and restaurant reviews to provide a more relevant and tailored result.
- Reasoning and Inference: Search engines can draw inferences and conclusions based on the relationships between data. For instance, if a user searches for “causes of climate change,” the search engine can return results that are not only about the causes but also about their interconnectedness and impact.
- Data Integration: Search engines can integrate data from multiple sources, providing a more holistic view of the subject. Imagine searching for “historical events in Europe” and getting a single result page that integrates data from different historical databases, museums, and academic journals.
- Automated Knowledge Extraction: Search engines can automatically extract knowledge from unstructured data, such as text and images, using semantic analysis. This will allow for the discovery of previously hidden knowledge.
- Semantic Similarity Search: Search engines can find results that are semantically similar to the user’s query, even if the words used are different. For example, finding results about “artificial intelligence” when the user searches for “machine learning”.
These advancements in information access and retrieval will lead to a more informed and connected world. The Semantic Web will be instrumental in enabling more accurate, insightful, and accessible knowledge for everyone.
Human-Computer Interaction
The Semantic Web, by its very nature, aims to bridge the gap between human understanding and machine comprehension. This has profound implications for how we interact with computers, promising a future where communication is more intuitive and knowledge sharing is seamless. By representing knowledge in a structured, machine-readable format, the Semantic Web enables computers to understand the context and meaning behind human queries and actions, fostering a more natural and efficient interaction.The Semantic Web transforms the interaction paradigm by moving away from -based searches towards a deeper understanding of meaning.
This shift allows for more accurate and relevant information retrieval, reducing the cognitive load on the user and providing a richer, more meaningful experience. This transition is crucial for navigating the vast and ever-growing digital landscape.
Improved Knowledge Sharing
The Semantic Web facilitates a more nuanced approach to knowledge sharing by connecting different pieces of information in a logical and meaningful way. This allows users to easily discover relationships between concepts, identify relevant information, and explore new areas of knowledge. The potential for improved knowledge sharing extends to collaborative projects and research endeavors. Individuals can seamlessly contribute to and draw from a shared pool of knowledge, fostering a dynamic and collaborative learning environment.
Implications on Human-Information Interaction
The Semantic Web’s impact on human-information interaction is multifaceted. Instead of merely searching for s, users will interact with information through a deeper understanding of its context and meaning. This shift in paradigm allows for more efficient and effective information retrieval, reducing the cognitive burden on the user and offering a richer, more meaningful experience.
Design Considerations for Intuitive Interfaces
Effective interfaces for the Semantic Web require careful design considerations. They must be intuitive, allowing users to interact with information in a natural and meaningful way. Interface elements should clearly reflect the relationships between concepts, allowing users to effortlessly navigate and explore knowledge. Visualization plays a vital role in conveying complex relationships in a comprehensible manner. Using visual cues, diagrams, and charts to represent data structures can greatly enhance user understanding and interaction.
Examples of Semantic Web Interfaces, The future of human knowledge the semantic web
While fully realized semantic web interfaces are still evolving, several prototypes and early implementations demonstrate the potential. Some examples include applications that leverage semantic technologies to provide richer search results, connect related documents, and suggest relevant information based on user context. These early demonstrations showcase the ability of semantic technologies to improve information access and retrieval, though widespread adoption still awaits more robust infrastructure and standardized implementations.
Furthermore, semantic technologies can be used to create personalized learning environments that adapt to individual needs and preferences. Imagine an e-learning platform that can dynamically tailor the content and pace of learning based on a user’s semantic profile.
Ethical Considerations
The Semantic Web, while promising a future of enhanced knowledge access and understanding, presents complex ethical challenges. As knowledge becomes more interconnected and accessible, ensuring its responsible use and preventing potential misuse becomes paramount. The very nature of a globally interconnected knowledge base demands careful consideration of biases, potential harms, and the need for ethical frameworks to guide its development and application.The potential for misuse of knowledge represented in the Semantic Web is significant, ranging from the spread of misinformation to the reinforcement of harmful stereotypes.
This necessitates proactive measures to address ethical concerns and develop robust mechanisms to mitigate potential risks. A deep understanding of the potential ethical implications is crucial for the responsible development and deployment of this technology.
Potential Risks and Biases
The representation of knowledge in the Semantic Web can inadvertently perpetuate existing biases and stereotypes. Machine learning algorithms trained on biased data can lead to discriminatory outcomes in various applications. For example, if a knowledge graph is populated with information reflecting historical inequalities, it could reinforce these biases and perpetuate harmful stereotypes in areas such as hiring or loan applications.
Furthermore, the lack of transparency in how algorithms process information can hinder the identification and mitigation of biases.
Examples of Ethical Concerns in Different Application Domains
- Healthcare: Using patient data in a semantic web application for research or diagnosis could lead to privacy violations or misinterpretations. A system that links medical records to genetic information might lead to unfair discrimination against certain groups. Robust data anonymization and secure access protocols are crucial for addressing these issues.
- Education: Semantic web-based learning platforms could potentially create unequal learning opportunities if the knowledge representation isn’t accessible to all learners. The development of content and data should strive to be inclusive and avoid marginalizing any particular group. Addressing language barriers and accessibility issues is vital for equitable access to education.
- Law Enforcement: The use of knowledge graphs for criminal investigations could raise significant privacy concerns. Misuse of data could lead to wrongful accusations or biased investigations. Strong ethical guidelines and oversight mechanisms are necessary to ensure responsible use.
Strategies to Address Ethical Challenges
- Bias Detection and Mitigation: Developing methods to identify and mitigate biases in knowledge representation is essential. This involves employing techniques like fairness-aware machine learning and incorporating diverse datasets into the training process. Regular audits and independent reviews are also necessary to detect and address potential biases.
- Transparency and Explainability: Ensuring transparency in how knowledge graphs are constructed and how algorithms operate is crucial for building trust and understanding. Explainable AI (XAI) methods can be employed to provide insights into the reasoning behind specific outputs. This transparency allows for the identification and correction of errors and biases.
- Data Privacy and Security: Protecting sensitive data is paramount. Robust security measures, such as encryption and access controls, are vital for preventing unauthorized access and misuse. Clear data governance policies and protocols must be in place to safeguard privacy and ensure responsible data handling.
Ultimate Conclusion
In conclusion, the semantic web presents a powerful vision for the future of human knowledge, promising to revolutionize information access and retrieval. While challenges remain, the potential benefits are substantial, particularly in areas like education, research, and business. As we move forward, careful consideration of ethical implications and practical implementation strategies will be crucial for realizing the full potential of this groundbreaking technology.