
You can subscribe to the system design newsletter to excel in system design interviews and software architecture. The original article was published on systemdesign.one website.
In the intricate world of distributed systems, where countless machines collaborate to deliver seamless services, maintaining consistent and up-to-date information across all nodes is a monumental challenge. Traditional approaches often falter under the weight of scale and the inevitability of failures. Emerging as a powerful solution, the gossip protocol, also known as the epidemic protocol, offers a decentralized and robust mechanism for information dissemination and state synchronization. This article delves into the mechanics, applications, advantages, and disadvantages of gossip protocols, providing a comprehensive overview for understanding their critical role in modern software architecture.
The Fundamental Challenges of Distributed Systems
Distributed systems, by their very nature, are prone to several inherent complexities. The core problems typically encountered include:
- Node Failures: Individual machines can crash or become unresponsive due to hardware malfunctions, software bugs, or power outages.
- Network Partitions: The network connecting nodes can split, isolating groups of machines from each other, leading to conflicting views of the system state.
- Message Loss: Network issues can cause data packets to be dropped, preventing information from reaching its intended destination.
- Concurrency Issues: Multiple nodes attempting to update the same data simultaneously can lead to race conditions and inconsistent states.
- Scalability Bottlenecks: As the number of nodes increases, centralized components or inefficient communication patterns can become performance bottlenecks.
Traditional Approaches and Their Limitations
To address these challenges, various strategies have been employed. One common approach involves centralized state management services, such as Apache ZooKeeper. These services act as a single source of truth, tracking the state of every node in the system. While offering strong consistency guarantees, this model suffers from a critical flaw: the centralized service becomes a single point of failure. If the management service goes down, the entire distributed system can be compromised. Furthermore, for extremely large-scale systems, these centralized entities can become significant scalability bottlenecks.
In contrast, peer-to-peer state management services aim for high availability and eventual consistency. This is where the gossip protocol truly shines. By enabling nodes to communicate directly with each other in a decentralized manner, gossip protocols achieve remarkable scalability and resilience, even in the face of widespread failures.
Understanding the Gossip Protocol: An Epidemic Analogy
The name "gossip protocol" itself evokes the informal spread of information. Its design is directly inspired by how rumors or diseases spread through a population. In an epidemic, an infected individual encounters others and passes on the contagion, which then spreads further. Similarly, in a gossip protocol, nodes periodically exchange information with a randomly selected subset of their peers. This process, repeated over time, ensures that information eventually propagates throughout the entire network with a high probability.
This analogy highlights a key characteristic: probabilistic convergence. While there’s no absolute guarantee that every single piece of information will reach every single node instantaneously, the likelihood of complete dissemination increases exponentially with each round of communication. This makes the gossip protocol exceptionally well-suited for scenarios where immediate, strong consistency isn’t paramount, but high availability and eventual consistency are critical.
Broadcast Protocols: A Comparative View
To appreciate the elegance of the gossip protocol, it’s useful to contrast it with other message broadcasting techniques:
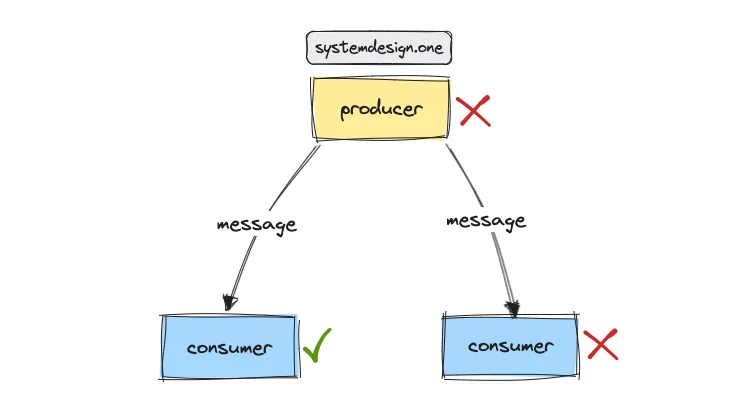
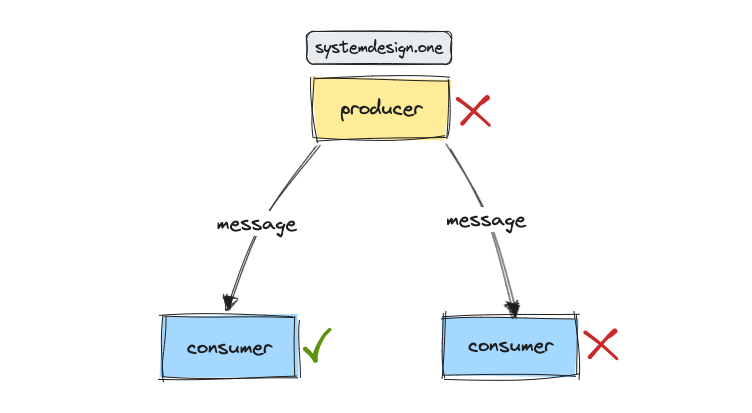
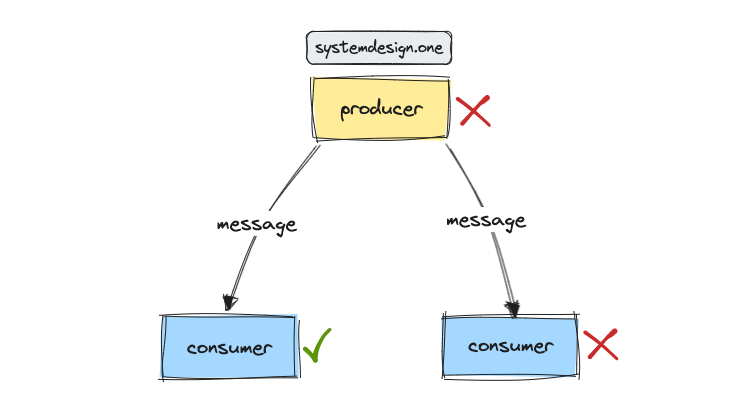
Point-to-Point Broadcast
In a simple point-to-point broadcast, a producer directly sends a message to each consumer. Reliability is typically achieved through retry mechanisms on the producer’s side and deduplication on the consumer’s side. However, this approach is vulnerable to simultaneous failures of both the producer and the consumer, leading to message loss.
Eager Reliable Broadcast
This method involves every node re-broadcasting messages to all other nodes via reliable network links. This offers improved fault tolerance, as remaining nodes can continue the dissemination if some fail. The primary drawbacks are the significant network overhead and potential for message duplication if not managed carefully.
Gossip Protocol as a Decentralized Broadcast
The gossip protocol offers a decentralized alternative. Instead of broadcasting to everyone or directly to individuals, each node acts as a "gossiper." Periodically, a node selects a small, random subset of other nodes and shares its current knowledge. This limited, local interaction builds a global picture over time. The protocol is inherently scalable because each node’s communication load is independent of the total number of nodes in the system.
Types of Gossip Protocols
Gossip protocols can be broadly categorized based on their primary function and information exchange strategy:
Anti-Entropy Gossip Protocol
The anti-entropy protocol aims to reduce the "entropy" or disorder between replicas of data. Nodes periodically exchange their entire datasets or summaries thereof, identifying discrepancies and synchronizing them. While effective for ensuring data consistency, this can be bandwidth-intensive. Techniques like checksums, Merkle trees, and lists of recent updates are employed to optimize this process by identifying only the differences, thus reducing unnecessary data transfers. The anti-entropy protocol, if not carefully managed, can lead to an unbounded number of messages without a clear termination point.
Rumor-Mongering Gossip Protocol
Also known as the dissemination protocol, rumor-mongering focuses on efficiently spreading new information. Cycles of rumor-mongering are typically more frequent than anti-entropy cycles and are designed to flood the network with the latest updates. This model is generally more efficient in terms of bandwidth usage, as it primarily transmits only the most recent information. To prevent perpetual message flooding, messages are often marked for removal after a certain number of communication rounds. This strategy offers a high probability that a message will reach all nodes.
Aggregation Gossip Protocol
This variant is designed to compute system-wide aggregates. Nodes sample information from their local state and combine it with information from their peers to generate a global aggregate value. This is useful for tasks like calculating average load across a cluster or monitoring system-wide metrics.
Strategies for Message Dissemination
Within the gossip framework, several strategies can be employed for spreading messages:
- Push Model: A node with new information actively sends it to a random subset of its peers. This is efficient when there are few updates, minimizing network traffic.
- Pull Model: Nodes actively poll a random subset of their peers to check for any new updates. This is beneficial when there are many updates, as it increases the likelihood of finding a node with the latest information.
- Push-Pull Model: This hybrid approach combines the strengths of both push and pull. A node can push new updates and also pull for any missing information. This is often considered optimal for rapid and reliable dissemination, particularly in dynamic environments.
Performance Characteristics and Parameters
The efficiency and speed of gossip protocols are influenced by key parameters:
- Fanout: The number of other nodes a given node sends messages to in each gossip round. A higher fanout can lead to faster dissemination but increases network load.
- Cycle (or Interval): The frequency at which nodes initiate gossip exchanges. Shorter intervals lead to faster propagation but also higher traffic.
The time required for a message to propagate across a network of ‘n’ nodes using a gossip protocol is generally logarithmic with respect to the fanout. For example, in a cluster of 25,000 nodes, it might take approximately 15 gossip rounds. With a gossip interval as low as 10 milliseconds, a message could theoretically spread across a large data center in a matter of seconds.
Case studies, such as one involving a system with 128 nodes, have demonstrated the efficiency of gossip protocols, reporting negligible CPU usage (less than 2%) and minimal bandwidth consumption (less than 60 KBps) for running the protocol.
Key Properties and Algorithm Overview
Gossip protocols are characterized by several desirable properties:
- Scalability: As discussed, the per-node communication load remains constant regardless of system size.
- Fault Tolerance: The decentralized and redundant nature of communication makes the system resilient to node failures and network partitions.
- Robustness: The symmetric design ensures that the failure of a single node does not cripple the system.
- Convergent Consistency: The system eventually converges to a consistent state, albeit not necessarily instantaneously.
- Decentralization: No single point of control or failure exists.
- Simplicity: Many gossip protocol variants are relatively straightforward to implement.
- Integration and Interoperability: Gossip protocols can be integrated with various distributed system components.
- Bounded Load: The protocol generates predictable and manageable network traffic.
The high-level gossip algorithm typically involves nodes periodically selecting random peers, exchanging their current state (or relevant parts of it), and updating their own state based on the received information. Heartbeat counters are often used to track node liveness; a stagnant counter indicates a potential failure or network partition.
Implementation Details and Peer Selection
Gossip protocols can operate over UDP or TCP, with configurable fanout and intervals. A crucial component is the peer sampling service, which uses randomized algorithms to select peers for message exchange. This service typically provides mechanisms for adding new nodes, removing nodes, and retrieving a random sample of live nodes.
The process often begins with seed nodes, which are static, known nodes that help bootstrap new nodes into the cluster and prevent logical network divisions. When a node starts, it typically exchanges its full metadata with seed nodes. To optimize subsequent exchanges, nodes can maintain version numbers or use generation clocks (monotonically increasing numbers incremented on node restarts) to track metadata changes and send only incremental updates.
A typical gossip exchange involves a node sending a "gossip digest synchronization" message containing information about its own state and its perceived state of other nodes. This is met with a "gossip digest acknowledgment" message from the recipient, which might also include its own updates. This exchange allows nodes to maintain a partial, yet evolving, view of the system’s membership and state.
Real-World Use Cases and Applications
The versatility of gossip protocols makes them indispensable in a wide array of distributed systems. Some prominent use cases include:
- Membership Management: Keeping track of which nodes are currently active and available in a cluster.
- Failure Detection: Identifying unresponsive or failed nodes with high probability. This is far more reliable than relying on single client interactions, as it accounts for network partitions and individual client failures.
- State Synchronization: Propagating application-level data, configuration changes, and operational metrics across nodes.
- Distributed Counter Systems: As seen in systems like Amazon Dynamo and distributed counters, gossip can help maintain eventually consistent counts.
- Cluster Management: Tools like Apache Cassandra heavily rely on gossip for cluster membership and failure detection.
- Service Discovery: Although often handled by dedicated services, gossip can contribute to decentralized service discovery mechanisms.
- Monitoring and Health Checks: Transmitting node statistics like average load and memory usage to inform local decision-making and global system health.
Advantages of Gossip Protocols
The widespread adoption of gossip protocols is driven by their significant advantages:
Scalability
The logarithmic convergence time and constant per-node communication complexity make gossip protocols exceptionally scalable for large distributed systems.
Fault Tolerance
The inherent redundancy, parallelism, and randomness in message routing make the system highly resilient to node failures, network partitions, and message loss.
Robustness
The decentralized and symmetric nature of the protocol ensures that the failure of individual nodes does not disrupt the overall system’s functionality.
Convergent Consistency
While not providing strong consistency immediately, gossip protocols guarantee that the system will eventually reach a consistent state, which is sufficient for many applications.
Decentralization
The absence of a central authority eliminates single points of failure and simplifies system architecture.
Simplicity
The core logic of most gossip protocols is relatively easy to understand and implement.
Integration and Interoperability
With well-defined interfaces and data formats, gossip can seamlessly integrate with other distributed components.
Bounded Load
The protocol’s predictable message generation and peer selection strategies ensure that individual system components are not overwhelmed.
Disadvantages and Challenges
Despite their strengths, gossip protocols are not without their limitations:
Eventual Consistency
The primary trade-off for high availability and scalability is the eventual consistency model. This means there will be a delay before all nodes reflect the latest state, which may not be suitable for applications requiring immediate strong consistency.
Network Partition Unawareness
While tolerant of network issues, gossip protocols are inherently unaware of network partitions. Nodes within isolated partitions will continue to gossip amongst themselves, potentially delaying the propagation of information across the entire system once the partition is resolved.
Bandwidth Consumption
In certain scenarios, especially with frequent updates or large message payloads, the same information might be retransmitted multiple times, leading to inefficient bandwidth usage. The effective fanout can degrade if the volume of information to be gossiped exceeds the bounded message size.
Latency
The reliance on periodic intervals for message exchange, rather than immediate event-driven transmission, introduces latency. A message must wait for the next scheduled gossip cycle to be sent.
Debugging and Testing Challenges
The inherent non-determinism and distributed nature of gossip protocols can make debugging and reproducing failures exceptionally difficult. Advanced tools like simulation, emulation, and comprehensive logging are often required.
Scalability (Membership Protocol Dependency)
While the gossip protocol itself is scalable, some implementations may rely on non-scalable underlying membership protocols, which can become a bottleneck.
Computational Error
In the presence of malicious nodes, gossip protocols can be susceptible to computational errors. Implementing self-correcting mechanisms, encryption, authentication, and reputation systems is crucial for security and integrity.
Conclusion
Gossip protocols represent a powerful paradigm for building highly available, scalable, and resilient distributed systems. By mimicking the natural spread of information, they offer a robust and decentralized approach to state synchronization and failure detection. While the trade-off of eventual consistency and potential for increased latency and bandwidth usage must be considered, the benefits of gossip protocols in large-scale environments are undeniable. As distributed systems continue to grow in complexity and scale, the principles of gossip will likely remain a cornerstone of effective system design, enabling the seamless operation of the digital infrastructure that underpins our modern world.









{kind=link}